Um den Anforderungen von Cloud-Diensten gerecht zu werden, wird das Netzwerk schrittweise in Underlay und Overlay unterteilt. Das Underlay-Netzwerk umfasst die physische Infrastruktur wie Routing und Switching im traditionellen Rechenzentrum, die weiterhin auf Stabilität setzt und zuverlässige Datenübertragung gewährleistet. Das Overlay-Netzwerk hingegen ist das darauf aufbauende Geschäftsnetzwerk, das näher am Nutzer arbeitet und über VXLAN- oder GRE-Protokollkapselung benutzerfreundliche Netzwerkdienste bereitstellt. Underlay- und Overlay-Netzwerk sind miteinander verbunden und gleichzeitig voneinander entkoppelt; sie beeinflussen sich gegenseitig und können sich unabhängig voneinander weiterentwickeln.
Das Underlay-Netzwerk bildet die Grundlage des Gesamtnetzwerks. Ist es instabil, kann die Service-Level-Vereinbarung (SLA) nicht eingehalten werden. Nach der dreischichtigen Netzwerkarchitektur und der Fat-Tree-Architektur vollzieht sich in Rechenzentren der Übergang zur Spine-Leaf-Architektur, wodurch die dritte Anwendung des CLOS-Netzwerkmodells ermöglicht wird.
Traditionelle Rechenzentrumsnetzwerkarchitektur
Dreischichtiges Design
Von 2004 bis 2007 war die dreistufige Netzwerkarchitektur in Rechenzentren sehr verbreitet. Sie besteht aus drei Schichten: der Kernschicht (dem Hochgeschwindigkeits-Switching-Backbone des Netzwerks), der Aggregationsschicht (die richtlinienbasierte Verbindungen bereitstellt) und der Zugriffsschicht (die Arbeitsstationen mit dem Netzwerk verbindet). Das Modell sieht wie folgt aus:
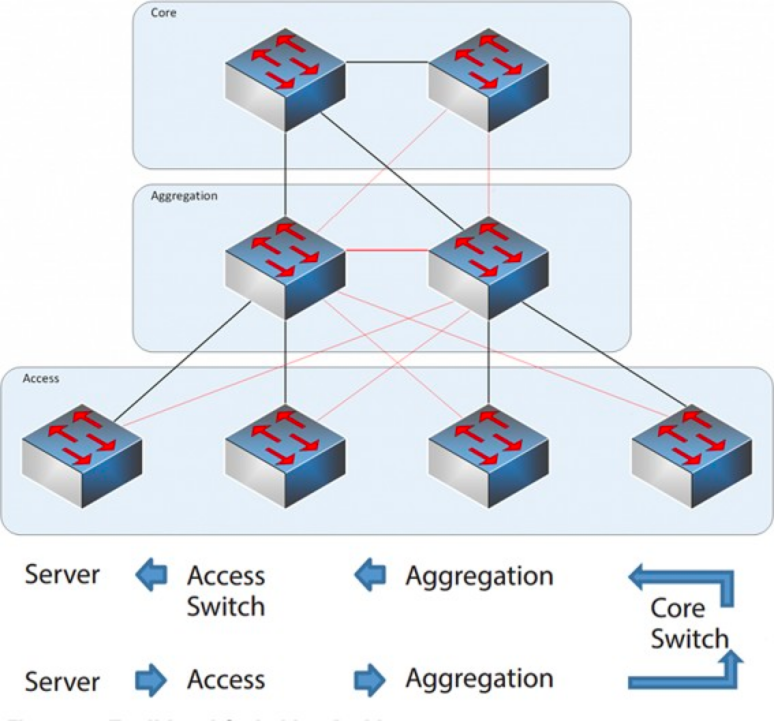
Dreischichtige Netzwerkarchitektur
Kernschicht: Die Kern-Switches ermöglichen die schnelle Weiterleitung von Paketen in und aus dem Rechenzentrum, die Anbindung an die verschiedenen Aggregationsschichten und ein ausfallsicheres L3-Routing-Netzwerk, das typischerweise das gesamte Netzwerk bedient.
Aggregationsschicht: Der Aggregations-Switch verbindet sich mit dem Zugriffs-Switch und bietet weitere Dienste wie Firewall, SSL-Offloading, Intrusion Detection, Netzwerkanalyse usw.
Zugriffsschicht: Die Zugriffsswitches befinden sich üblicherweise oben im Rack, daher werden sie auch ToR-Switches (Top of Rack) genannt und stellen die physische Verbindung zu den Servern her.
Der Aggregations-Switch bildet typischerweise die Trennlinie zwischen L2- und L3-Netzwerken: Das L2-Netzwerk befindet sich unterhalb des Aggregations-Switches, das L3-Netzwerk darüber. Jede Gruppe von Aggregations-Switches verwaltet einen Point of Delivery (POD), und jeder POD ist ein unabhängiges VLAN-Netzwerk.
Netzwerkschleifen- und Spannbaumprotokoll
Die Bildung von Schleifen wird hauptsächlich durch Verwirrung aufgrund unklarer Zielpfade verursacht. Beim Aufbau von Netzwerken verwenden Anwender zur Gewährleistung der Zuverlässigkeit üblicherweise redundante Geräte und Verbindungen, wodurch Schleifen unvermeidlich entstehen. Da sich das Layer-2-Netzwerk in derselben Broadcast-Domäne befindet, werden Broadcast-Pakete in der Schleife wiederholt übertragen, was zu einem Broadcast-Sturm führt. Dieser kann Portblockaden und Geräteausfälle verursachen. Um Broadcast-Stürme zu verhindern, ist es daher notwendig, die Bildung von Schleifen zu unterbinden.
Um Schleifenbildung zu verhindern und die Zuverlässigkeit zu gewährleisten, können redundante Geräte und Verbindungen nur als Backup-Geräte und -Verbindungen fungieren. Das heißt, die Ports und Verbindungen redundanter Geräte sind im Normalbetrieb gesperrt und nehmen nicht an der Weiterleitung von Datenpaketen teil. Nur wenn das aktuell weiterleitende Gerät, der Port oder die Verbindung ausfällt und dadurch eine Netzwerküberlastung entsteht, werden die Ports und Verbindungen redundanter Geräte geöffnet, um den normalen Netzwerkbetrieb wiederherzustellen. Diese automatische Steuerung wird durch das Spanning Tree Protocol (STP) realisiert.
Das Spanning Tree Protocol (STP) arbeitet zwischen der Zugriffsschicht und der Zielschicht. Kernstück ist ein Spanning-Tree-Algorithmus, der auf jeder STP-fähigen Bridge ausgeführt wird und speziell dafür entwickelt wurde, Schleifenbildung bei redundanten Pfaden zu vermeiden. STP wählt den optimalen Datenpfad für die Weiterleitung von Nachrichten aus und blockiert Verbindungen, die nicht Teil des Spanning Trees sind. Dadurch bleibt zwischen je zwei Netzwerkknoten nur ein aktiver Pfad bestehen, während die andere Uplink-Verbindung blockiert wird.
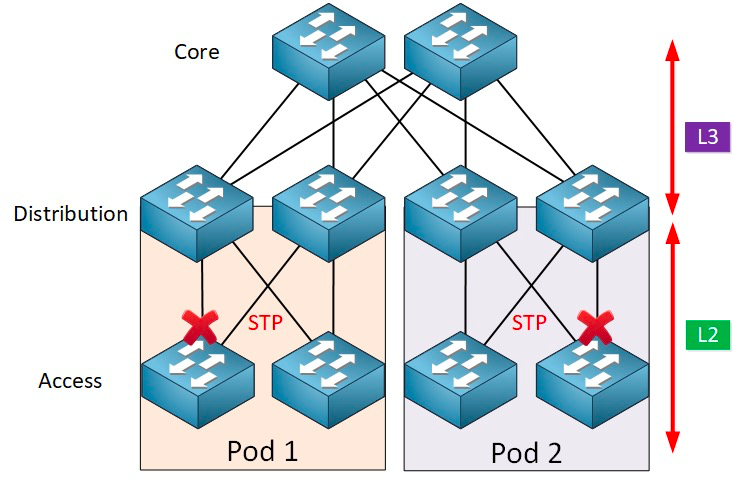
STP bietet viele Vorteile: Es ist einfach, sofort einsatzbereit und erfordert nur minimalen Konfigurationsaufwand. Die Maschinen innerhalb jedes Pods gehören zum selben VLAN, sodass der Server seinen Standort innerhalb des Pods beliebig verschieben kann, ohne die IP-Adresse und das Gateway zu ändern.
Parallele Weiterleitungspfade können jedoch von STP nicht genutzt werden, da redundante Pfade innerhalb des VLANs stets deaktiviert werden. Nachteile von STP:
1. Langsame Konvergenz der Topologie. Bei einer Änderung der Netzwerktopologie benötigt das Spanning Tree Protocol 50-52 Sekunden, um die Topologiekonvergenz abzuschließen.
2. Es kann keine Lastverteilung gewährleisten. Bei einer Schleife im Netzwerk kann das Spanning-Tree-Protokoll die Schleife lediglich blockieren, sodass die Verbindung keine Datenpakete weiterleiten kann und Netzwerkressourcen verschwendet werden.
Virtualisierung und Herausforderungen im Ost-West-Verkehr
Nach 2010 begannen Rechenzentren, Virtualisierungstechnologien einzuführen, um die Auslastung ihrer Rechen- und Speicherressourcen zu verbessern. Dadurch entstanden zahlreiche virtuelle Maschinen (VMs) im Netzwerk. Die Virtualisierungstechnologie wandelt einen Server in mehrere logische Server um. Jede VM kann unabhängig laufen, verfügt über ein eigenes Betriebssystem, eigene Anwendungen, eine eigene MAC-Adresse und IP-Adresse und verbindet sich über einen virtuellen Switch (vSwitch) innerhalb des Servers mit externen Systemen.
Virtualisierung erfordert eine weitere wichtige Funktion: die Live-Migration virtueller Maschinen. Diese ermöglicht es, ein System virtueller Maschinen von einem physischen Server auf einen anderen zu verschieben und dabei den laufenden Betrieb der Dienste auf den virtuellen Maschinen aufrechtzuerhalten. Dieser Prozess ist für Endbenutzer unauffällig. Administratoren können Serverressourcen flexibel zuweisen oder physische Server reparieren und aufrüsten, ohne die normale Nutzung durch die Benutzer zu beeinträchtigen.
Um einen unterbrechungsfreien Betrieb während der Migration zu gewährleisten, muss nicht nur die IP-Adresse der virtuellen Maschine unverändert bleiben, sondern auch ihr Betriebszustand (z. B. der TCP-Sitzungsstatus) muss während der Migration erhalten bleiben. Daher ist eine dynamische Migration der virtuellen Maschine nur innerhalb derselben Layer-2-Domäne möglich, nicht jedoch über eine andere Layer-2-Domäne hinweg. Dies erfordert größere Layer-2-Domänen von der Zugriffsschicht bis zur Kernschicht.
In der traditionellen Layer-2-Netzwerkarchitektur liegt die Trennlinie zwischen L2 und L3 am Core-Switch. Das Rechenzentrum unterhalb des Core-Switches bildet eine vollständige Broadcast-Domäne, also das L2-Netzwerk. Dadurch lassen sich Geräte flexibel platzieren und Standorte verlagern, ohne dass die IP- und Gateway-Konfiguration angepasst werden muss. Die verschiedenen L2-Netzwerke (VLANs) werden über die Core-Switches geroutet. Allerdings muss der Core-Switch in dieser Architektur eine umfangreiche MAC- und ARP-Tabelle verwalten, was hohe Anforderungen an seine Leistungsfähigkeit stellt. Zusätzlich begrenzt der Access-Switch (TOR) die Skalierbarkeit des gesamten Netzwerks. Dies führt letztendlich zu Einschränkungen hinsichtlich Skalierbarkeit, Erweiterungsmöglichkeiten und Elastizität des Netzwerks. Verzögerungen bei der Planung zwischen den drei Layern können zukünftigen Geschäftsanforderungen nicht gerecht werden.
Andererseits stellt der durch die Virtualisierungstechnologie bedingte Ost-West-Verkehr auch das traditionelle dreischichtige Netzwerk vor Herausforderungen. Der Datenverkehr in Rechenzentren lässt sich grob in folgende Kategorien unterteilen:
Nord-Süd-Verkehr:Datenverkehr zwischen Clients außerhalb des Rechenzentrums und dem Server im Rechenzentrum bzw. Datenverkehr vom Server im Rechenzentrum ins Internet.
Ost-West-Verkehr:Datenverkehr zwischen Servern innerhalb eines Rechenzentrums sowie Datenverkehr zwischen verschiedenen Rechenzentren, wie z. B. Notfallwiederherstellung zwischen Rechenzentren, Kommunikation zwischen privaten und öffentlichen Clouds.
Die Einführung der Virtualisierungstechnologie führt zu einer zunehmend verteilten Bereitstellung von Anwendungen, und der „Nebeneffekt“ ist, dass der Ost-West-Verkehr zunimmt.
Traditionelle dreigeschossige Architekturen sind typischerweise für den Nord-Süd-Verkehr ausgelegt.Obwohl es für den Ost-West-Verkehr genutzt werden kann, erfüllt es möglicherweise nicht die erforderlichen Anforderungen.
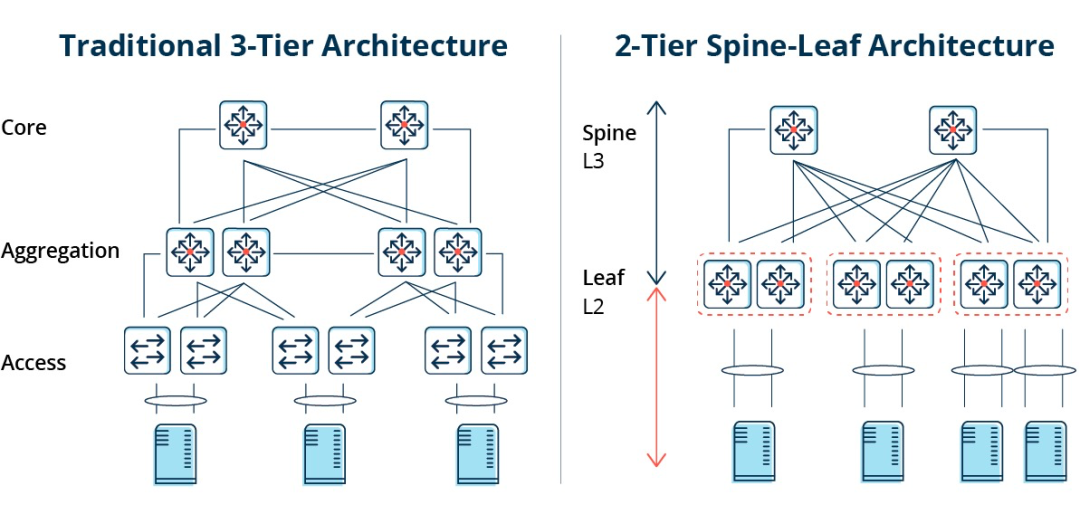
Traditionelle dreigeschossige Architektur vs. Spine-Leaf-Architektur
In einer dreistufigen Architektur muss der Ost-West-Datenverkehr über Geräte der Aggregations- und Kernschicht weitergeleitet werden. Dadurch werden unnötigerweise viele Knoten durchlaufen. (Server -> Zugriff -> Aggregation -> Kern-Switch -> Aggregation -> Zugriffs-Switch -> Server)
Wenn also eine große Menge Ost-West-Datenverkehr über eine herkömmliche dreistufige Netzwerkarchitektur läuft, können Geräte, die an denselben Switch-Port angeschlossen sind, um Bandbreite konkurrieren, was zu schlechten Reaktionszeiten für die Endbenutzer führt.
Nachteile der traditionellen dreischichtigen Netzwerkarchitektur
Es zeigt sich, dass die traditionelle dreischichtige Netzwerkarchitektur viele Mängel aufweist:
Bandbreitenverschwendung:Um Schleifenbildung zu vermeiden, wird üblicherweise das STP-Protokoll zwischen der Aggregationsschicht und der Zugriffsschicht eingesetzt, sodass nur ein Uplink des Zugriffsswitches tatsächlich Datenverkehr überträgt und die anderen Uplinks blockiert werden, was zu einer Verschwendung von Bandbreite führt.
Schwierigkeiten bei der Platzierung großflächiger Netzwerke:Mit der Erweiterung des Netzwerkmaßstabs verteilen sich Rechenzentren auf verschiedene geografische Standorte, virtuelle Maschinen müssen erstellt und überall migriert werden, und ihre Netzwerkattribute wie IP-Adressen und Gateways bleiben unverändert, was die Unterstützung von Fat Layer 2 erfordert. In der traditionellen Struktur ist eine Migration nicht möglich.
Mangelnder Ost-West-Verkehr:Die dreistufige Netzwerkarchitektur ist primär für den Nord-Süd-Verkehr ausgelegt, unterstützt zwar auch den Ost-West-Verkehr, weist aber deutliche Schwächen auf. Bei hohem Ost-West-Verkehr steigt die Belastung der Switches in der Aggregations- und Kernschicht erheblich, wodurch die Netzwerkgröße und -leistung auf diese beiden Schichten beschränkt werden.
Dies führt dazu, dass Unternehmen in das Dilemma zwischen Kosten und Skalierbarkeit geraten:Der Betrieb großflächiger Hochleistungsnetze erfordert eine große Anzahl an Geräten für die Konvergenz- und Kernschicht. Dies verursacht nicht nur hohe Kosten für Unternehmen, sondern erfordert auch eine sorgfältige Planung beim Netzaufbau. Bei kleinen Netzen führt dies zu Ressourcenverschwendung, und bei wachsendem Umfang wird die Erweiterung schwierig.
Die Spine-Leaf-Netzwerkarchitektur
Was ist die Spine-Leaf-Netzwerkarchitektur?
Als Antwort auf die oben genannten ProblemeEs hat sich ein neues Rechenzentrumsdesign herausgebildet, die Spine-Leaf-Netzwerkarchitektur, die wir auch als Blattgratnetzwerk bezeichnen.
Wie der Name schon sagt, verfügt die Architektur über eine Spine-Schicht und eine Leaf-Schicht, einschließlich Spine-Switches und Leaf-Switches.
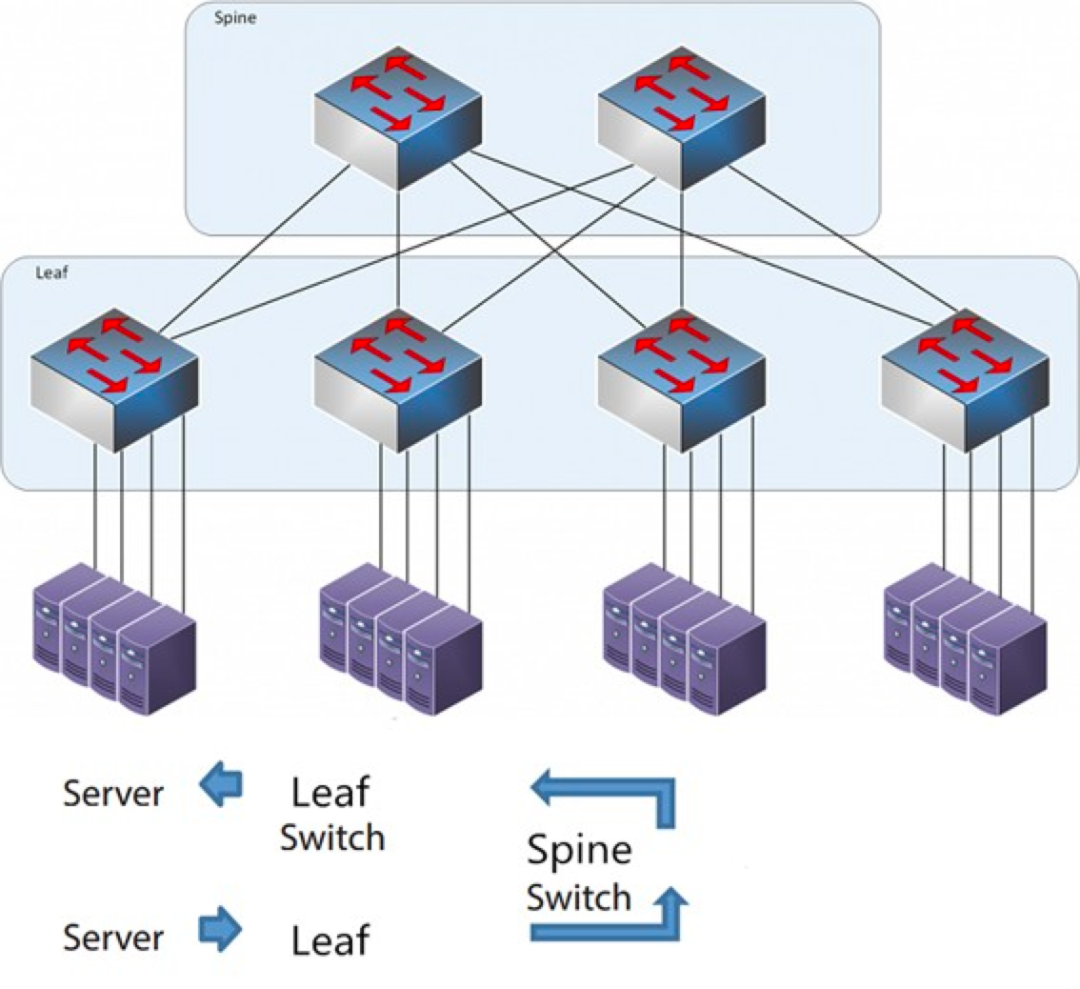
Die Dorn-Blatt-Architektur
Jeder Blattschalter ist mit allen Mittelstreifenschaltern verbunden, die nicht direkt miteinander verbunden sind, wodurch eine vollständig vermaschte Topologie entsteht.
Bei einer Spine-Leaf-Architektur durchläuft eine Verbindung von einem Server zu einem anderen immer die gleiche Anzahl an Geräten (Server → Leaf → Spine-Switch → Leaf-Switch → Server), was eine vorhersehbare Latenz gewährleistet. Denn ein Datenpaket muss nur einen Spine-Switch und einen Leaf-Switch durchlaufen, um sein Ziel zu erreichen.
Wie funktioniert Spine-Leaf?
Leaf-Switch: Er entspricht dem Access-Switch in der traditionellen dreischichtigen Architektur und ist als Top-of-Rack-Switch (TOR) direkt mit dem physischen Server verbunden. Der Unterschied zum Access-Switch besteht darin, dass die Trennlinie zwischen L2- und L3-Netzwerk nun auf dem Leaf-Switch liegt. Der Leaf-Switch befindet sich oberhalb des dreischichtigen Netzwerks und unterhalb der unabhängigen L2-Broadcast-Domäne. Dadurch wird das Problem der Netzwerkblockierung (BUM) großer zweischichtiger Netzwerke gelöst. Wenn zwei Leaf-Server kommunizieren müssen, ist L3-Routing erforderlich, das über einen Spine-Switch weitergeleitet wird.
Spine-Switch: Entspricht einem Core-Switch. ECMP (Equal Cost Multi Path) wird verwendet, um dynamisch mehrere Pfade zwischen Spine- und Leaf-Switches auszuwählen. Der Unterschied besteht darin, dass der Spine-Switch nun ein ausfallsicheres L3-Routing-Netzwerk für den Leaf-Switch bereitstellt, sodass der Nord-Süd-Verkehr des Rechenzentrums über den Spine-Switch anstatt direkt geroutet werden kann. Der Nord-Süd-Verkehr kann vom Edge-Switch parallel zum Leaf-Switch zum WAN-Router geleitet werden.
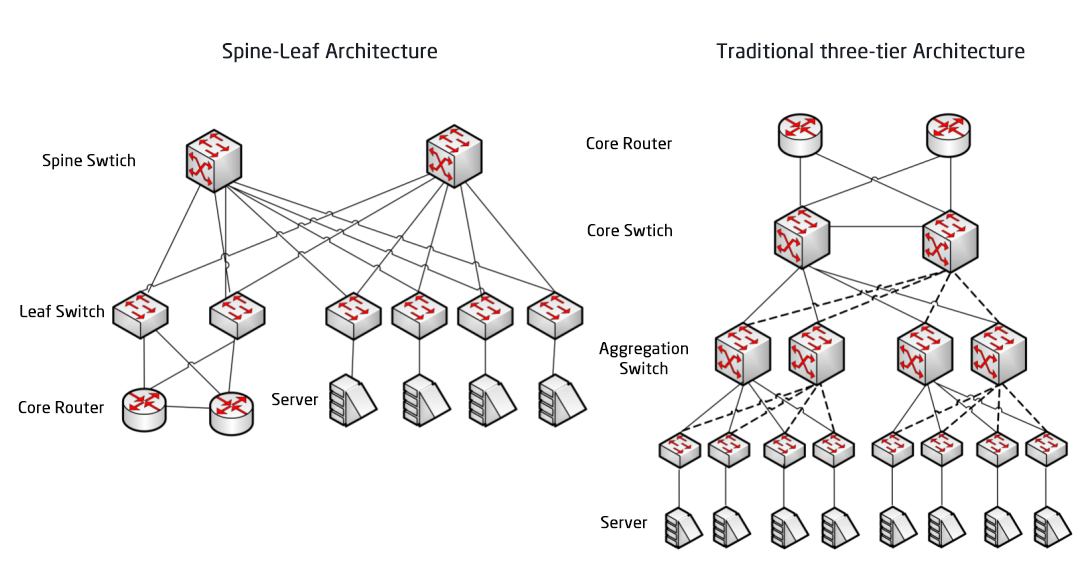
Vergleich zwischen Spine/Leaf-Netzwerkarchitektur und traditioneller dreischichtiger Netzwerkarchitektur
Vorteile der Dornen-Blatt-Methode
Wohnung:Ein flaches Design verkürzt den Kommunikationsweg zwischen Servern, was zu geringeren Latenzzeiten führt und die Anwendungs- und Serviceleistung deutlich verbessern kann.
Gute Skalierbarkeit:Bei unzureichender Bandbreite kann die Bandbreite durch Hinzufügen weiterer Ridge-Switches horizontal erweitert werden. Steigt die Anzahl der Server, können Leaf-Switches hinzugefügt werden, falls die Portdichte nicht ausreicht.
Kostenreduzierung: Nord- und Südverkehr, ausgehend entweder von Blattknoten oder von Mittelknoten. Ost-West-Verkehr, verteilt auf mehrere Pfade. Dadurch kann das Blatt-Mittelknoten-Netzwerk mit fest konfigurierten Switches arbeiten, ohne dass teure modulare Switches benötigt werden, und somit die Kosten senken.
Niedrige Latenz und Vermeidung von Überlastung:In einem Leaf-Ridge-Netzwerk durchlaufen Datenflüsse unabhängig von Quelle und Ziel immer die gleiche Anzahl an Hops. Jeweils zwei Server sind über drei Hops (Leaf → Spine → Leaf) erreichbar. Dadurch entsteht ein direkterer Datenpfad, was die Leistung verbessert und Engpässe reduziert.
Hohe Sicherheit und Verfügbarkeit:Das STP-Protokoll wird in der traditionellen dreistufigen Netzwerkarchitektur verwendet. Fällt ein Gerät aus, kommt es zu einer Rekonvergenz, die die Netzwerkleistung beeinträchtigt oder sogar zum Ausfall führen kann. In der Leaf-Ridge-Architektur hingegen ist bei einem Geräteausfall keine Rekonvergenz erforderlich, und der Datenverkehr wird über andere, normale Pfade weitergeleitet. Die Netzwerkverbindung bleibt unbeeinträchtigt, und die Bandbreite reduziert sich lediglich um einen Pfad, was die Leistung nur geringfügig beeinträchtigt.
Lastverteilung via ECMP eignet sich besonders für Umgebungen mit zentralisierten Netzwerkmanagementplattformen wie SDN. SDN vereinfacht die Konfiguration, Verwaltung und Umleitung des Datenverkehrs bei Blockierungen oder Verbindungsfehlern und macht die intelligente Lastverteilung in einer vollständig vermaschten Topologie zu einer relativ einfachen Methode für Konfiguration und Verwaltung.
Die Spine-Leaf-Architektur hat jedoch einige Einschränkungen:
Ein Nachteil besteht darin, dass die Anzahl der Switches die Netzwerkgröße erhöht. Bei der Leaf-Ridge-Netzwerkarchitektur muss die Anzahl der Switches und Netzwerkgeräte im Rechenzentrum proportional zur Anzahl der Clients erhöht werden. Mit steigender Anzahl an Hosts wird eine große Anzahl von Leaf-Switches benötigt, um die Verbindung zum Ridge-Switch herzustellen.
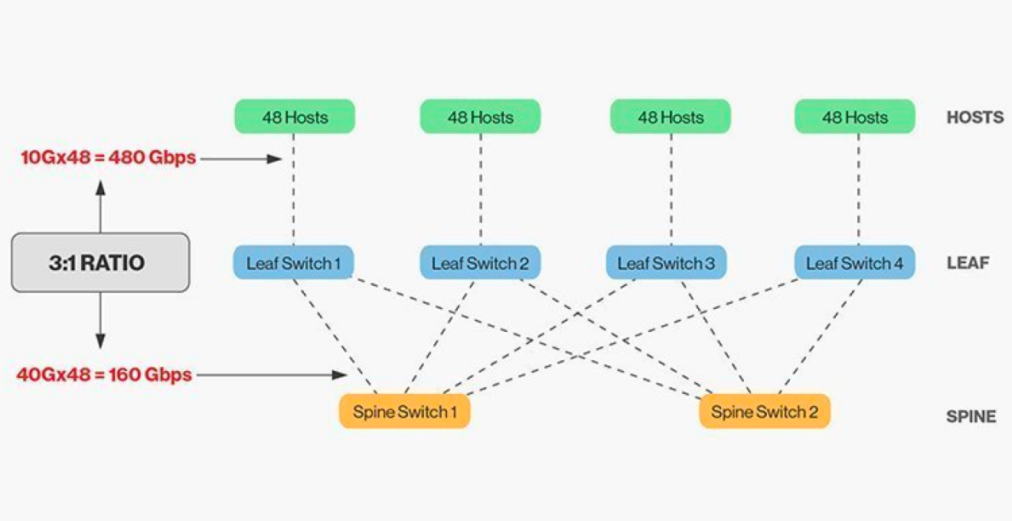
Die direkte Verbindung von Steg- und Blattschaltern erfordert eine Anpassung, und im Allgemeinen darf das sinnvolle Bandbreitenverhältnis zwischen Blatt- und Stegschaltern 3:1 nicht überschreiten.
Beispielsweise sind an einem Leaf-Switch 48 Clients mit einer Datenrate von 10 Gbit/s angeschlossen, was einer Gesamtkapazität der Ports von 480 Gbit/s entspricht. Werden die vier 40G-Uplink-Ports jedes Leaf-Switches mit dem 40G-Ridge-Switch verbunden, ergibt sich eine Uplink-Kapazität von 160 Gbit/s. Das Verhältnis beträgt 480:160 bzw. 3:1. Uplinks in Rechenzentren arbeiten typischerweise mit 40G oder 100G und können schrittweise von anfänglich 40G (N x 40G) auf 100G (N x 100G) migriert werden. Wichtig ist, dass der Uplink stets schneller als der Downlink sein sollte, um eine Blockierung der Portverbindung zu vermeiden.
Spine-Leaf-Netzwerke stellen besondere Anforderungen an die Verkabelung. Da jeder Leaf-Knoten mit jedem Spine-Switch verbunden sein muss, ist die Verlegung zusätzlicher Kupfer- oder Glasfaserkabel erforderlich. Die Entfernung der Verbindungen treibt die Kosten in die Höhe. Je nach Abstand zwischen den verbundenen Switches benötigt die Spine-Leaf-Architektur ein Vielfaches an hochwertigen optischen Modulen im Vergleich zur herkömmlichen dreistufigen Architektur, was die Gesamtkosten der Implementierung erhöht. Dies hat jedoch zu einem Wachstum des Marktes für optische Module geführt, insbesondere für Hochgeschwindigkeitsmodule wie 100G und 400G.
Veröffentlichungsdatum: 26. Januar 2026



